



- English – US
- English – India
- English - Malaysia
- English - Singapore
- 日本語 (Japanese)
- 简体中文 (Simplified Chinese)
- 繁體中文 (Traditional Chinese)
英特尔®、美光™和 Supermicro® 非常自豪地宣布,我们在 STAC-M3 基准测试中创造了 25 项新的世界纪录!没错,就是 25 项!STAC-M3 是一套行业标准的金融企业交易数据分析基准测试套件,用于测试金融行业中用来管理大量实时逐笔市场数据(“交易数据”)的数据库软件和硬件堆栈。测试分为基准测试(名为“Antuco”)和更大规模的可扩展性测试(名为“Kanaga”)两类。
该解决方案基于英特尔 6767P Xeon 6 处理器、美光 9550 NVMe SSD、美光 128GB DDR5 RDIMM 和 Supermicro SSG-222B-NE3X24R Petascale 服务器,其测试结果优于所有目前公开披露的相关报告,并创造了 25 项新的性能纪录:
- 24 项 Kanaga 平均响应时间基准指标中的 19 项,包括 50 用户和 100 用户配置下的全部 10 项 Kanaga 基准指标
- 5 项 Kanaga 吞吐量基准指标中的 3 项
- 50 用户和 100 用户配置下的全部 3 项 Antuco 基准指标
在本博客中,我们将重点介绍 Kanaga 和 Antuco 中规模最大的测试项目,展示该方案仅用远少于此前纪录保持者的硬件配置,便能实现卓越性能。
 图 1:6 个 Supermicro SSG-222B-NE3X24R Petascale 服务器节点
图 1:6 个 Supermicro SSG-222B-NE3X24R Petascale 服务器节点
(点击图片放大)
系统架构
在深入探讨测试结果之前,让我们先看看参加测试的系统配置:
我们使用了 6 台 Supermicro SSG-222B-NE3X24R Petascale 服务器,通过 400GbE 进行集群连接。每台服务器的硬件配置如下:
- 2 颗 英特尔 Xeon 6767P 处理器,单颗 64 核,单节点 128 个计算核,集群共计 768 核
- 16 条 128GB 美光 DDR5 DRAM,单节点内存容量 2TB,集群总内存 12TB
- 24 块 12.8TB 美光 9550 NVMe SSD,单节点存储容量 307.2TB,集群总存储 1,843TB
- 2 个 400GbE ConnectX-7 SmartNIC,单节点网络吞吐量 100GB/s,集群总吞吐量 600GB/s
该解决方案在 KX Software 的 kdb+ 4.1 上运行,搭配测试套件为STAC-M3 Pack kdb+ 版。
STAC-M3 基准测试套件
分析时间序列数据(如逐条交易记录和交易历史数据),对于算法开发、风险管理等金融行业所需功能至关重要。随着自动交易的普及,特别是高频交易策略的流行,上述分析变得愈加关键和复杂。随着交易机器人试图在微秒乃至亚微秒级竞争中占据先机,其产生的报价与交易数据量极为庞大。这种情况下,能够高效、快速地存储和分析此类活动的技术,变得更加重要。
STAC 基准测试委员会开发了 STAC-M3 基准测试套件,为量化新兴软件、云和硬件创新在提升交易数据的存储、检索和分析性能方面提供了统一标准。
STAC-M3 根据工作负载规模分为两类基准测试:
- Antuco:旨在衡量单节点性能的小规模基准测试
- Kanaga:Antuco 的扩展版本,适用于测试大规模硬件部署的负载能力
虽然我们的 STAC-M3 报告包括了两类基准测试中所有测试项的详细结果,但在本博客中,我们将重点关注使用最大数据集的 Kanaga 测试的结果。
STAC-M3 会不断扩展数据集的大小,先从一个小数据集开始,然后逐年扩展,每年的数据集大小是上一年的 1.6 倍,以这种方式连续扩展 5 年。“第 5 年”的数据集代表了参与测试的最大数据集,也是参与测试的解决方案处理起来最困难的数据集。STAC-M3 基准测试使用以毫秒为单位的延迟值作为测试结果;因此数值越低表示性能越优。
解决方案对比
STAC-M3 测试支持多种硬件配置;组件选择由被测系统的设计架构师决定。就我们的解决方案而言,我们主要关注三个影响性能的因素:
- 密度:我们能否比其他解决方案的占用空间更少?
- 总拥有成本 (TCO):我们的解决方案是否具备成本效益,规模配置是否合理?
- 可扩展性:我们的解决方案能否突破当前测试配置的限制,实现进一步扩展?
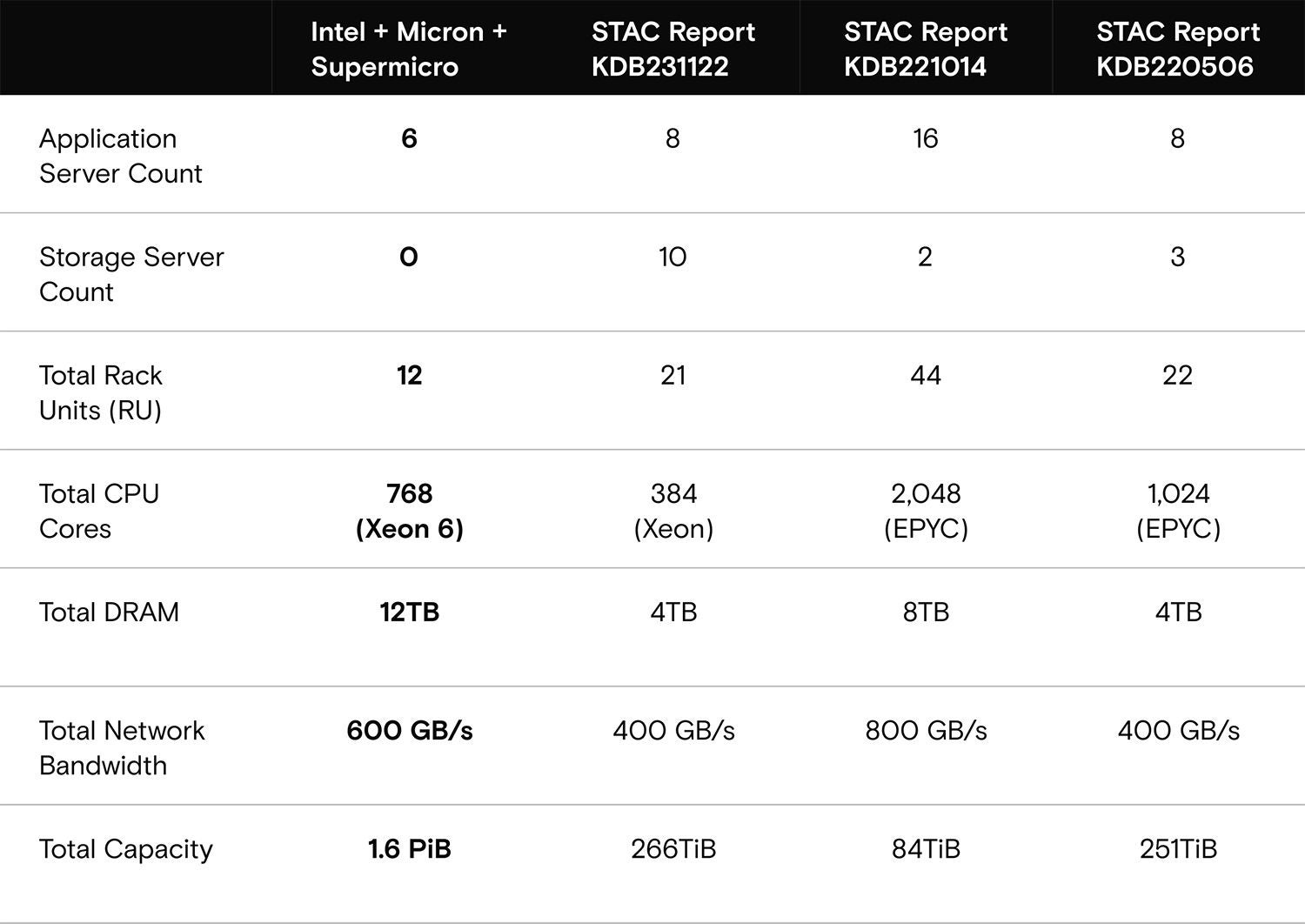 表 1:与先前纪录保持者的 STAC-M3 性能比较
表 1:与先前纪录保持者的 STAC-M3 性能比较
(点击图片放大)
我们将我们的解决方案与最近发布的三份 STAC-M3 报告进行了比较:
- 机架单元 (RU) 占用空间最小:我们:12RU;此前纪录保持者:21RU 至 44RU
- CPU 核心数位列第二少:我们:768 核;此前纪录保持者:384 至 2,048 核
- 我们的存储容量最大:我们:1.6PiB(相当于 1.8PB);此前纪录保持者:84TiB 至 266TiB
- 我们的内存容量最大:我们:12TB;此前纪录保持者:4TB 至 8TB
后续可以看出,我们的解决方案在占用空间大幅减少的情况下,性能显著优于之前的纪录保持者。
结果分析:不同时间区间的较高出价
5YRHIBID 测试项目使用单线程,返回数据集中特定年份范围内特定的 1% 交易代码中每个代码的最高出价。5YRHIBID 的时间范围为 2011 年第一天至 2015 年最后一天。这是一个读取密集型工作负载,算法方面的计算强度较低。
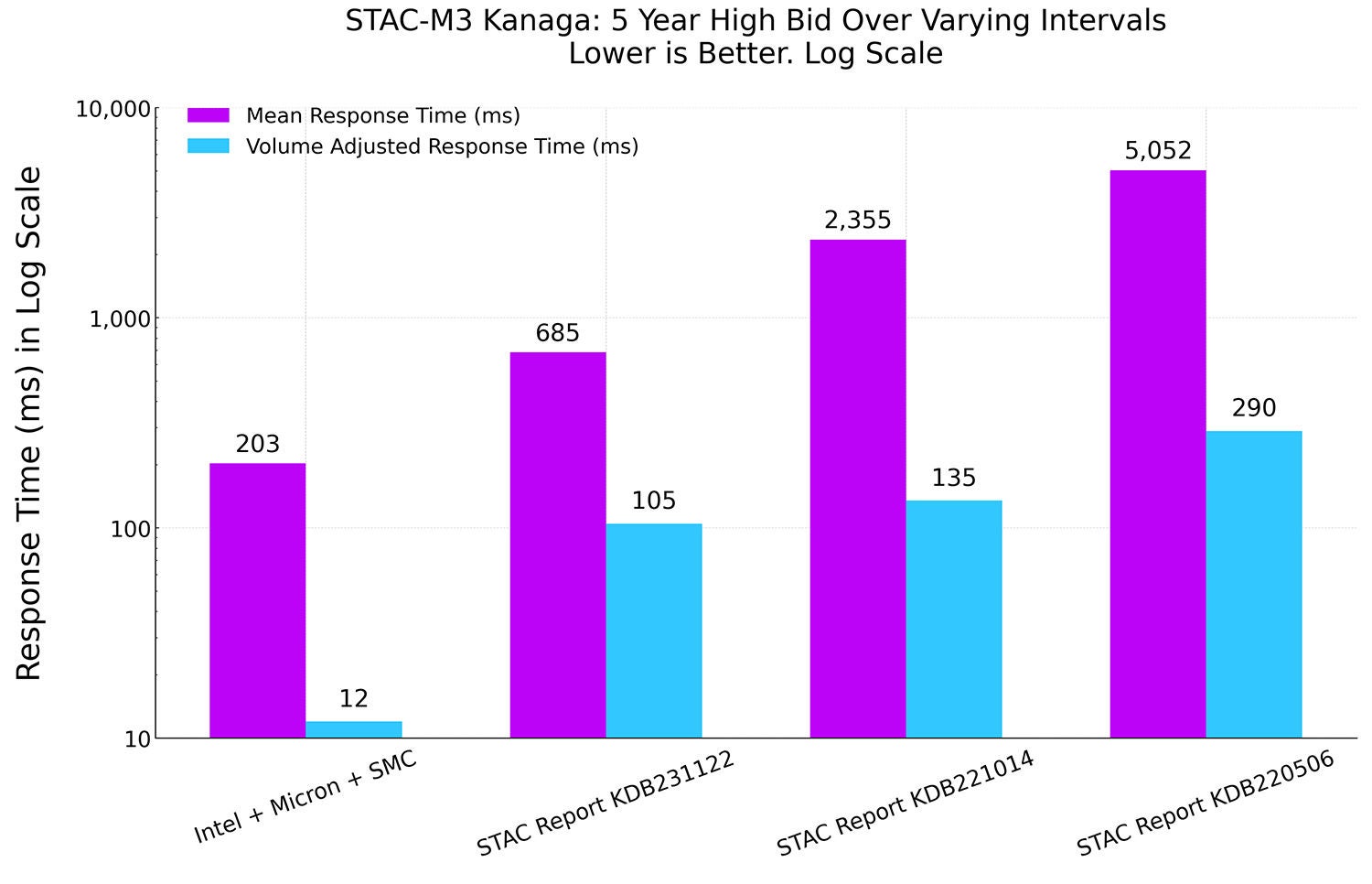 图 1:STAC-M3 Kanaga,第 5 年平均响应时间和交易量调整后响应时间(与之前纪录保持者对比)
图 1:STAC-M3 Kanaga,第 5 年平均响应时间和交易量调整后响应时间(与之前纪录保持者对比)
(点击图片放大)
响应时间显著缩短
与得分排名第二的参测方相比,我们的 STAC-M3 解决方案的平均响应时间缩短 70%,交易量调整后响应时间缩短 89%。交易量调整后响应时间是对原始响应时间的标准化处理,用于衡量每个报价或交易的响应时间随数据集规模变化的情况。请注意,上图中的单位为对数刻度。
美光 9550 NVMe SSD 之所以能大幅缩短响应时间,原因之一是其存储吞吐量大幅增加。
密度:存储性能大幅提高
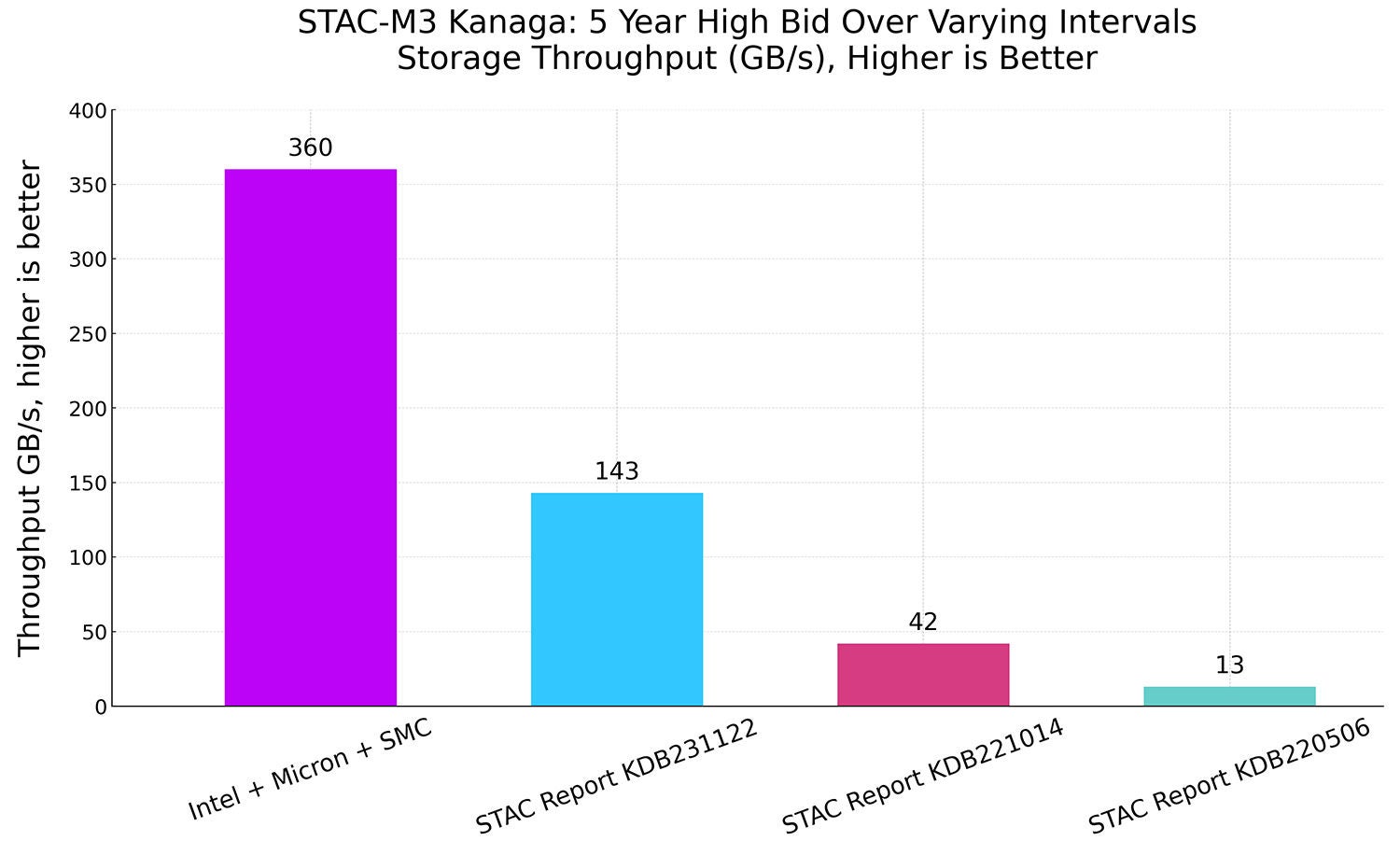 图 2:STAC-M3 Kanaga,5 年期不同时间区间高出价测试项目的存储吞吐量(与之前的纪录保持者对比,单位:GB/s)
图 2:STAC-M3 Kanaga,5 年期不同时间区间高出价测试项目的存储吞吐量(与之前的纪录保持者对比,单位:GB/s)
(点击图片放大)
在存储性能方面,我们的解决方案是排名第二的参测方的 2.5 倍以上,而我们的占用空间更小。
结果分析:不可预测区间统计
STATS-UI:每个用户查询“交易所 + 日期 + 开始时间”的唯一组合,然后返回在 100 分钟范围内、每个交易所在每分钟时间段内所有高交易量代码的基本统计数据。开始时间从整分钟时间点随机偏移,所有时间范围都会跨越日期边界。该工作负载兼具高读取密集型和高算法计算密集型特征。此类测试旨在衡量负载递增情况下的性能表现,特别是在 50 用户和 100 用户配置下的性能,代表了高并发场景下的情况。
速度:高并发场景下,计算和读取密集型查询用时最短
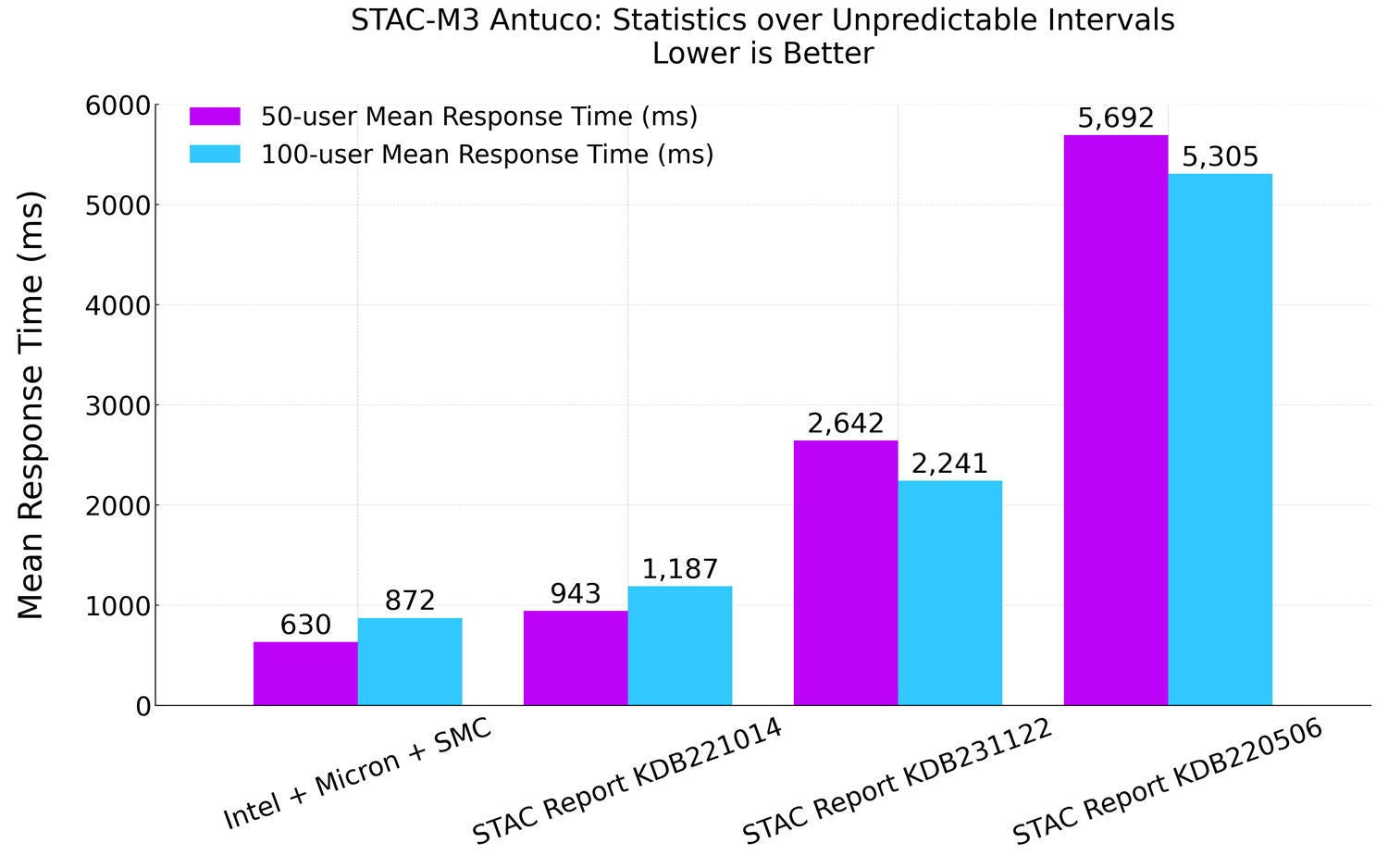 图 3:STAC-M3 Antuco,50 和 100 用户配置下的平均响应时间(与之前的纪录保持者对比)
图 3:STAC-M3 Antuco,50 和 100 用户配置下的平均响应时间(与之前的纪录保持者对比)
(点击图片放大)
与之前的纪录保持者 KDB221014 相比,我们的解决方案完成计算密集型 100 用户基准测试的时间缩短 36%,使用的 CPU 核心数量减少 62%。我们的解决方案在 100 用户配置下的平均响应时间甚至比 KDB221014 在 50 用户配置下的平均响应时间更短。
结果分析:第 5 年市场快照
YR5-MKTSNAP:在数据集中给定年份内的特定日期及特定时间,返回特定 1% 代码中每个代码的最新报价和交易的价格和规模。YR5-MKTSNAP 将在最大数据集中查询 2015 年内的日期和时间。该工作负载兼具高读取密集型与高算法计算密集型特征。
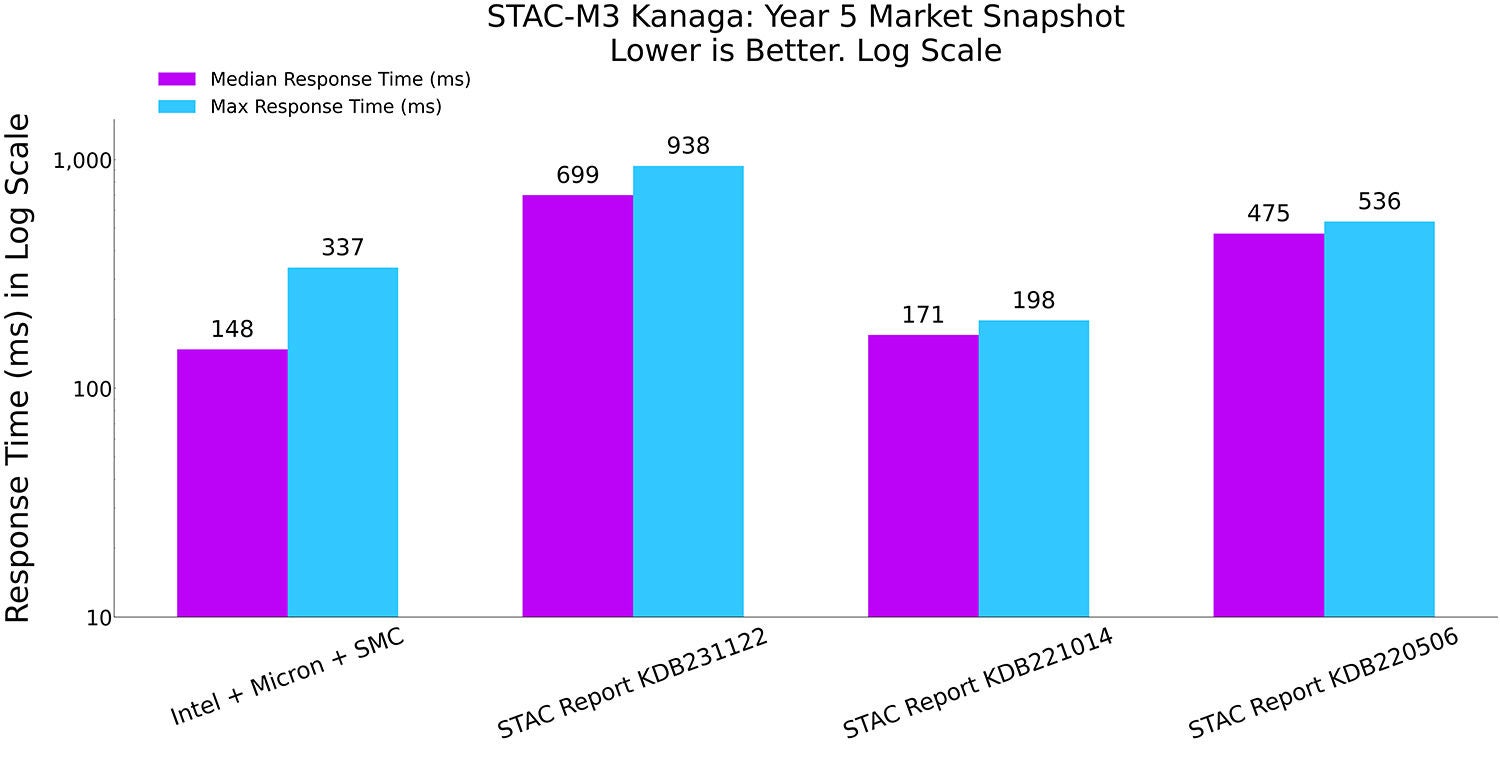 图 4:STAC-M3 Kanaga,第 5 年市场快照测试的中位和最大响应时间(与之前的纪录保持者对比)
图 4:STAC-M3 Kanaga,第 5 年市场快照测试的中位和最大响应时间(与之前的纪录保持者对比)
(点击图片放大)
TCO:以更少的核心数量和更少的机架空间实现出色性能
我们的解决方案的中位响应时间最短。虽然 KD2201014 报告中的最大响应时间最短,但该测试部署占用了 44RU 空间,使用了 2,048 个 CPU 核心,而我们的解决方案部署仅占用 12RU 空间,使用 768 个 CPU 核心。相比之下,我们以减少 62% 的 CPU 核心和 73% 的机架空间占用,实现了更快的中位数响应时间。
结果分析:第 5 年交易量加权出价
YR5 VWAB-12D-HO:随机选择的 12 天中的 4 小时交易量加权平均出价,并发请求的数量不等。该测试项运行在 Kanaga 的多年期数据集上,所选的日期和代码可确保请求间存在大量重叠——这与现实场景中的常见模式一致。该测试属于高读取密集型,算法计算强度较低。
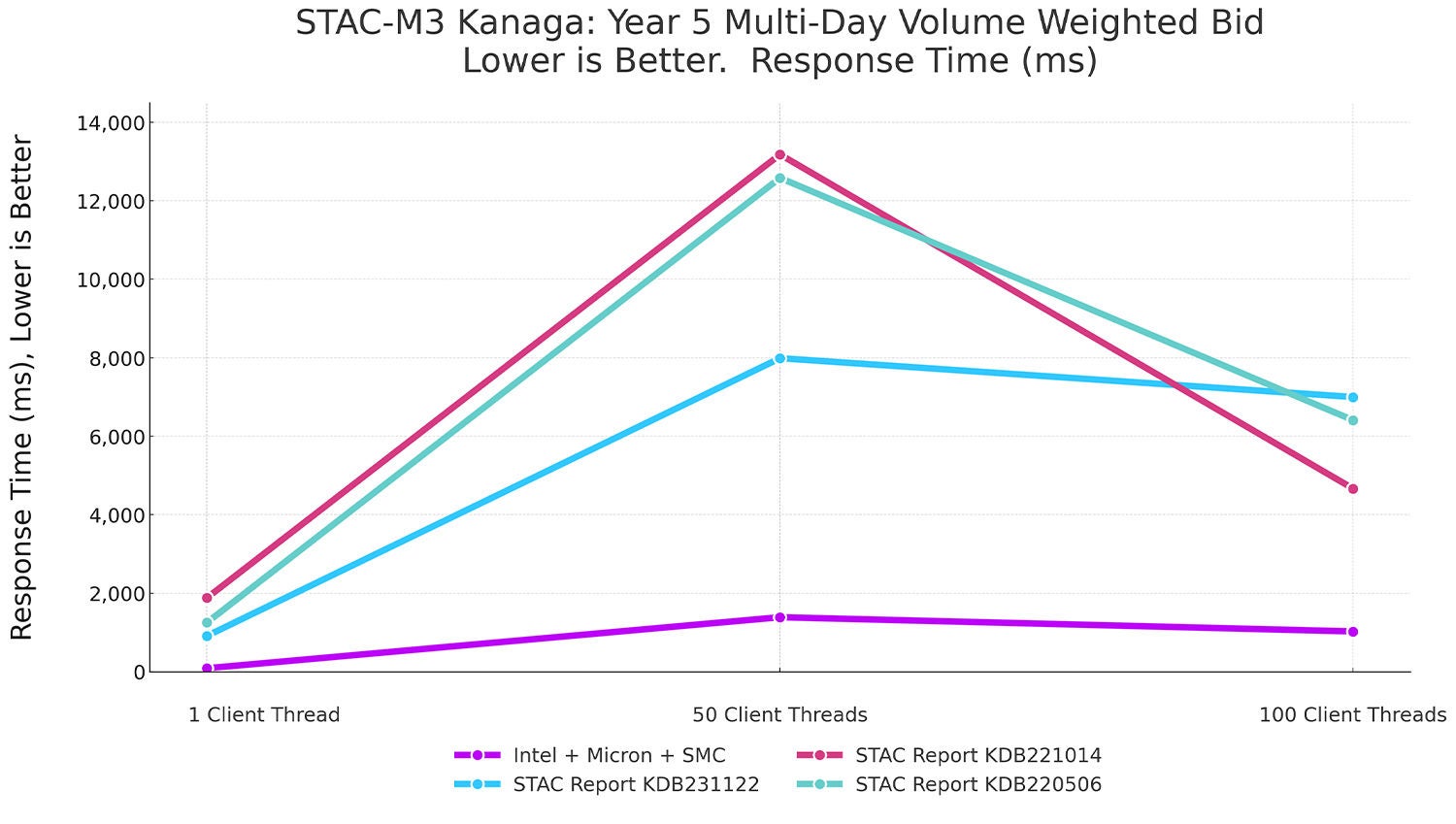 图 5:STAC-M3 Kanaga,第 5 年多日交易量加权出价(与之前的纪录保持者对比)
图 5:STAC-M3 Kanaga,第 5 年多日交易量加权出价(与之前的纪录保持者对比)
(点击图片放大)
该测试至关重要;体现了解决方案在用户负载增加时作出响应的能力。
可扩展性:用户扩展测试项的性能提高 10 倍
YR5 VWAB-12D-HO 的测试结果令人惊叹。在 1 个客户端线程配置下,我们的解决方案比所有已发布的报告快一个数量级。在 50 个客户端线程和 100 个客户端线程配置下,我们的解决方案保持着显著的领先优势,分别高达得分第二参测方的 9.5 倍和 7 倍。
解锁性能新前沿
基准测试的结果,向我们展示了真正的性能边界在哪里。新的纪录不断推动性能边界向前发展,重新定义硬件性能可能达到的新高度,激发整个行业产生新的想象力。当技术上的飞跃推动硬件速度极速提升,就会出现新的用例,曾经遥不可及的策略也会成为现实。历史数据处理越快,预见未来的视野就越远。
当计算、内存和存储通过工程设计协同工作时,会发生什么?答案是:向前推动硬件的性能边界。STAC-M3 是一个加强型测试套件,专门验证解决方案是否能满足金融服务领域的高要求工作负载。英特尔、美光和 Supermicro 通过资源整合,联手提供外观紧凑、可扩展的现代硬件堆栈解决方案,不仅打破了由大型服务器创下的纪录,更以突破性的性能提升大幅刷新了行业标杆。
想要了解更多信息?
- STAC-M3报告:KDB250929 6 台 Supermicro Petascale 服务器(每台搭载 2 颗英特尔® Xeon® 6767P 以及 24 块美光™ 9550 MAX NVMe™ SSD),适配 KDB+ 4.1
- Supermicro 新闻稿:Supermicro、英特尔和美光携手合作,在 STAC-M3TM 定量交易基准测试中创造多项新纪录
- 美光 9550 SSD |美光 DDR5 内存
如果您将于 10 月 28 日参加在纽约市举行的 STAC 大会,欢迎与该方案的架构师团队交流:
- 英特尔解决方案架构师 Kevin Gildea
- 美光首席数据中心解决方案架构师 Jay Walstrum
- Supermicro 存储市场开发总监 Wendell Wenjen
- 美光数据中心工作负载工程总监 Ryan Meredith

